Map Reduce 101 - Python Implementation (Multi Threading)
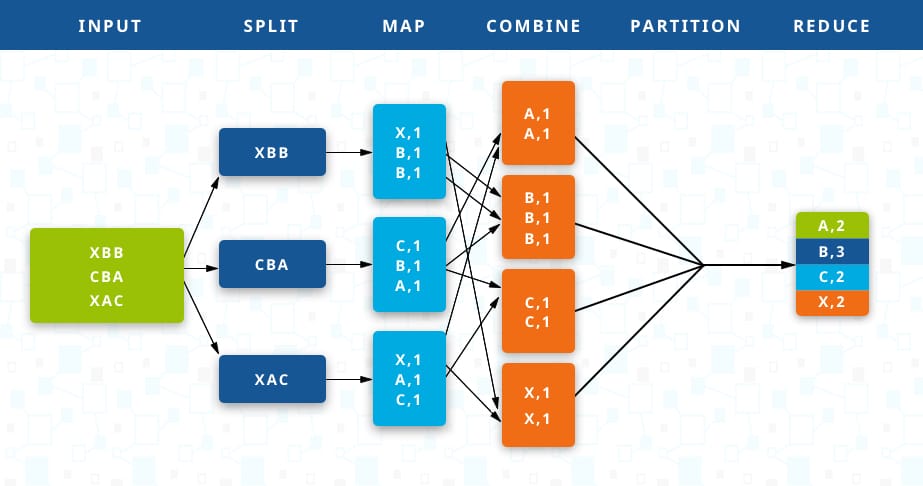 Image credit: Talend
Image credit: TalendI created a Mapper-Reducer implementation using basic features of Python to mimic Hadoop’s mapper-reducer functionality. I used Multi-threading (explained later) to run parallel operations. I used Google Colab to run the model and you can find the required [“Pride_and_Prejudice.txt”] file
here.
Goal
First, let’s map the words in the provided text to 1 using the mapper as <Word,1> and then use reducer to find the word count in the format <Word,Count>. A reducer also sorts the words which needs to be separately added to the series of operations. I implement the multi threading in python to parallelly get the word counts from two lists of words.
Input File
inputfile = open('/content/drive/My Drive/IDS561BigData/Assignment1/Pride_and_Prejudice.txt',"r")
text = inputfile.read()
Data cleaning
In order for us to use the text from the book, we have to remove the the punctuations, unnecessary numbers as they won’t help us understand the text in most cases.
We remove the numbers, convert the text to lower case using .lower() command and use Regular Expressions to replace punctuations with a space ' '. I then remove those Lines with no text in them.
def data_clean(text):
NoNumbers = ''.join([i for i in text if not i.isdigit()]) #Removing numbers
NoNumbers = text.lower() #Making the text to lower case
import re
onlyText = re.sub(r"[^a-z\s]+",' ',NoNumbers) #Removing punctuation
finaltext = "".join([s for s in onlyText.strip().splitlines(True) if s.strip()]) #Removing the null lines
return finaltext
Splitting data into two parts
Let’s define a reusable function which takes a list of words as input to do multi-threading on the given data set. Here “a” is the number of words after you wish to make the split. For example, splitlines(text,200) will split the text into split1 and split2 as two sentences with first 1 to 199 words in split1 and rest in split2.
def splitlines(text,a):
linessplit = text.splitlines() #Splitting the lines into a list
split1 = linessplit[0:a] #Creating the first split with the first "a" number of lines into split 1
split2 = linessplit[a:] #Creating the second split with the first "a" number of lines into split 2
return split1,split2
Mapper
We map all the words in “text” to 1 using the keyval.append([j,1]) command. So, the key here is the word and we apped a value of 1. The output format of the data is <word,1>.
def mapper(text,out_queue):
keyval = []
for i in text:
wordssplit = i.split()
for j in wordssplit:
keyval.append([j,1]) #Appending each word in the line with 1 and storing it in ["word",1] format in a nested list
out_queue.put(keyval)
Sorting Function
As we have two lists of separate key-value pairs after the split function, now we define sortging function to handle both the lists. We take two inputs and return only one output which which contains the sorted list of word key value pairs.
def sortedlists(list1,list2):
out = list1 + list2 #Appending the two input lists into a single list
out.sort(key= lambda x :x[0]) #Sorting the lists based on the first element of the list which is the "word"
return out
Partition
The below code creates two lists of sorted words in alphabetical order and then we separate the words starting with a-m and n-z. The function returns the sorted lists which will be inputs to the reducer function.
def partition(sorted_list) :
sort1out = []
sort2out = []
for i in sorted_list:
if i[0][0] < 'n': #Partitioning the sorted word list into two separate lists
sort1out.append(i) #with first list containing words starting with a-m and n-z into second
else : sort2out.append(i)
return sort1out,sort2out
Reducer
def reducer(part_out1,out_queue) :
sum_reduced = []
count = 1
for i in range(0,len(part_out1)):
if i < len(part_out1)-1:
if part_out1[i] == part_out1[i+1]:
count = count+1 #Counting the number of words
else :
sum_reduced.append([part_out1[i][0],count]) #Appending the word along with count to sum_reduced list as ["word",count]
count = 1
else: sum_reduced.append(part_out1[i]) #Appending the last word to the output list
out_queue.put(sum_reduced)
Multi - Threading function
The user defined function below takes a function and two inputs as arguments. The function is applied on both the inputs simultaneously and the output is returned by the function.
import threading
import queue
def multi_thread_function(func,map1_input,map2_input): #func is the function to be used with two threads taking two inputs map1_input and map2_input
my_queue1 = queue.Queue() #Using queue to store the values of mapper output to use them in sort function
my_queue2 = queue.Queue()
t1 = threading.Thread(target=func, args=(map1_input,my_queue1))
t2 = threading.Thread(target=func, args=(map2_input,my_queue2))
t1.start() #Starting the execution of thread1
t2.start() #Starting the execution of thread2 to run simultaneously with thread1
t1.join() #Waiting for the thread1 to be completely executed
t2.join() #Waiting for the thread2 to be completely executed
list1out = my_queue1.get() #Getting the values from the queue into a variable to return its value
list2out = my_queue2.get()
return list1out,list2out
Mapper-Reducer
Finally, we combine all the above functions to split the lines after 5000 words and them implement the entire Mapper Reducer operation which mimics the way Hadoop’s handles the data.
def main_function(text):
cleantext = data_clean(text)
linessplit = splitlines(cleantext,5000)
mapperout = multi_thread_function(mapper,linessplit[0],linessplit[1])
sortedwords = sortedlists(mapperout[0],mapperout[1])
slicedwords = partition(sortedwords)
reducerout = multi_thread_function(reducer,slicedwords[0],slicedwords[1])
return reducerout[0]+reducerout[1]
output = main_function(text)
import pandas as pd
pd.DataFrame(output).to_csv("Output.csv",index=False,header = ["Word","Frequency"]) #Saving file as a .csv file in the current directory
Did you find this page helpful? Consider sharing it 🙌
Vipanchi Reddy Katthula
Masters in Business Analytics
Data scientist with 3+ years of experience. Highly interested in NLP, Data Science and personal growth.